VOC dataset¶
Datasets¶
Sample flower dataset that contain total 280 images, belong to 2 species. Download
Extract the downloaded file in to data forder in project root like this
├── data
│ └── VOC2007
│ ├── Annotations
│ ├── ImageSets
│ ├── JPEGImages
│ └── pascal_label_map.pbtxt
Training on Jypiter Notebook¶
Import necessary modules¶
from faster_rcnn.utils.datasets.voc.voc import VOCDetection
import numpy as np
import torch
from faster_rcnn.utils.datasets.data_generator import CocoGenerator
from faster_rcnn.utils.datasets.data_generator import Enqueuer
from torch.optim import SGD
from faster_rcnn.faster_rcnn import FastRCNN, RPN
from pycrayon import CrayonClient
from torch.optim.lr_scheduler import StepLR
from datetime import datetime
from faster_rcnn.utils.datasets.adapter import convert_data
from faster_rcnn.utils.evaluate.metter import AverageMeter
from faster_rcnn.utils.display.images import imshow, result_show
Read Train and Validation datasets¶
root = '/data/data'
ds = VOCDetection(root, 'train')
val_ds = VOCDetection(root, 'val')
print(len(ds), len(val_ds))
Enqueue 2 datasets¶
batch_size = 3
data_gen = CocoGenerator(data=ds, batch_size=batch_size, shuffle=True)
queue = Enqueuer(generator=data_gen, use_multiprocessing=False)
queue.start(max_queue_size=20, workers=4)
train_data_generator = queue.get()
val_data_gen = CocoGenerator(data=ds, batch_size=batch_size, shuffle=True, seed=2)
val_queue = Enqueuer(generator=data_gen, use_multiprocessing=False)
val_queue.start(max_queue_size=20, workers=4)
val_data_generator = val_queue.get()
Create Faster RCNN Network¶
categories = ds.classes
print(categories)
net = FastRCNN(categories, debug=False)
net.cuda()
Select trainable parameters, and choose optimization strategy¶
params = filter(lambda x: x.requires_grad, net.parameters())
optimizer = SGD(params, lr=1e-4, momentum=0.9, weight_decay=0.0005)
exp_lr_scheduler = StepLR(optimizer, step_size=100, gamma=0.8)
Define Evaluate Function¶
def evaluate(data_gen ,model, steps_per_epoch, epochs=1):
exp_name = datetime.now().strftime('vgg16_%m-%d_%H-%M-%s')
cc = CrayonClient(hostname="crayon", port=8889)
exp = cc.create_experiment(exp_name)
model.eval()
val_loss = AverageMeter()
val_cross_entropy = AverageMeter()
val_loss_box = AverageMeter()
val_rpn_loss = AverageMeter()
for epoch in range(epochs):
for step in range(1, steps_per_epoch +1):
blobs = data_gen.next()
batch_tensor, im_info, batch_boxes, batch_boxes_index = convert_data(blobs)
cls_prob, bbox_pred, rois = model(batch_tensor, im_info, batch_boxes, batch_boxes_index)
loss = model.loss
val_loss_box.update(model.loss_box.item())
val_cross_entropy.update(model.cross_entropy.item())
val_loss.update(loss.item())
val_rpn_loss.update(model.rpn.loss.item())
log_text = 'val_loss: %.4f' % (val_loss.avg)
print(log_text)
return val_loss ,val_cross_entropy, val_loss_box, val_rpn_loss
Define Train Function¶
def train(train_data_gen, val_data_gen, optimizer, lr_scheduler ,model, epochs, steps_per_epoch, val_step_per_epoch):
exp_name = datetime.now().strftime('vgg16_%m-%d_%H-%M-%s')
cc = CrayonClient(hostname="crayon", port=8889)
exp = cc.create_experiment(exp_name)
train_loss = AverageMeter()
cross_entropy = AverageMeter()
loss_box = AverageMeter()
rpn_loss = AverageMeter()
current_step = 0
for epoch in range(epochs):
model.train()
for step in range(1, steps_per_epoch +1):
lr_scheduler.step()
blobs = data_gen.next()
batch_tensor, im_info, batch_boxes, batch_boxes_index = convert_data(blobs)
cls_prob, bbox_pred, rois = model(batch_tensor, im_info, batch_boxes, batch_boxes_index)
cls_data = cls_prob.data.cpu().numpy()
max_class_idx = np.argmax(cls_data, axis=1)
loss = model.loss
cross_entropy.update(model.cross_entropy.item())
loss_box.update(model.loss_box.item())
train_loss.update(loss.item())
rpn_loss.update(model.rpn.loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_step = epoch * steps_per_epoch + step
if step % 10 == 0:
log_text = 'epoch: %d : step %d, loss: %.4f' % (
epoch + 1, step , train_loss.avg)
print(log_text)
re_cnt = True
if step % 10 == 0:
exp.add_scalar_value('train_loss', train_loss.avg, step=current_step)
exp.add_scalar_value('rpn_loss', rpn_loss.avg, step=current_step)
exp.add_scalar_value('cross_entropy', cross_entropy.avg, step=current_step)
exp.add_scalar_value('loss_box', loss_box.avg, step=current_step)
torch.save(model.state_dict(), './checkpoints/faster_model_at_epoch_%s.pkl' % epoch + 1)
val_loss ,val_cross_entropy, val_loss_box, val_rpn_loss = evaluate(val_data_gen, model, val_step_per_epoch)
exp.add_scalar_value('val_loss', val_loss.avg, step=current_step)
exp.add_scalar_value('val_rpn_loss', val_rpn_loss.avg, step=current_step)
exp.add_scalar_value('val_cross_entropy', val_cross_entropy.avg, step=current_step)
exp.add_scalar_value('val_loss_box', val_loss_box.avg, step=current_step)
Train Network¶
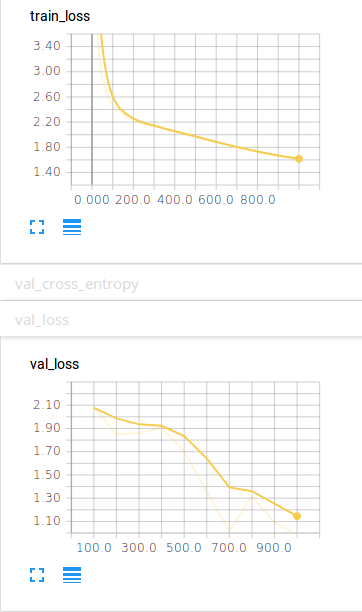
train(train_data_generator, val_data_generator ,optimizer=optimizer,lr_scheduler=exp_lr_scheduler, model=net, epochs=10, steps_per_epoch=100, val_step_per_epoch=15)
epoch: 1 : step 10, loss: 5.0192
epoch: 1 : step 20, loss: 3.9577
epoch: 1 : step 30, loss: 3.4115
epoch: 1 : step 40, loss: 3.1217
epoch: 1 : step 50, loss: 2.9148
epoch: 1 : step 60, loss: 2.7841
epoch: 1 : step 70, loss: 2.6765
epoch: 1 : step 80, loss: 2.5952
epoch: 1 : step 90, loss: 2.5265
epoch: 1 : step 100, loss: 2.4733
val_loss: 2.0767
epoch: 2 : step 10, loss: 2.4353
epoch: 2 : step 20, loss: 2.3974
epoch: 2 : step 30, loss: 2.3686
epoch: 2 : step 40, loss: 2.3471
epoch: 2 : step 50, loss: 2.3279
epoch: 2 : step 60, loss: 2.3041
epoch: 2 : step 70, loss: 2.2816
epoch: 2 : step 80, loss: 2.2663
epoch: 2 : step 90, loss: 2.2476
epoch: 2 : step 100, loss: 2.2308
val_loss: 1.8522
epoch: 3 : step 10, loss: 2.2142
epoch: 3 : step 20, loss: 2.2033
epoch: 3 : step 30, loss: 2.1916
epoch: 3 : step 40, loss: 2.1806
epoch: 3 : step 50, loss: 2.1749
epoch: 3 : step 60, loss: 2.1665
epoch: 3 : step 70, loss: 2.1589
epoch: 3 : step 80, loss: 2.1485
epoch: 3 : step 90, loss: 2.1395
epoch: 3 : step 100, loss: 2.1315
val_loss: 1.8585
epoch: 4 : step 10, loss: 2.1210
epoch: 4 : step 20, loss: 2.1123
epoch: 4 : step 30, loss: 2.1034
epoch: 4 : step 40, loss: 2.0959
epoch: 4 : step 50, loss: 2.0844
epoch: 4 : step 60, loss: 2.0772
epoch: 4 : step 70, loss: 2.0690
epoch: 4 : step 80, loss: 2.0610
epoch: 4 : step 90, loss: 2.0543
epoch: 4 : step 100, loss: 2.0450
val_loss: 1.9057
epoch: 5 : step 10, loss: 2.0351
epoch: 5 : step 20, loss: 2.0286
epoch: 5 : step 30, loss: 2.0205
epoch: 5 : step 40, loss: 2.0121
epoch: 5 : step 50, loss: 2.0036
epoch: 5 : step 60, loss: 1.9942
epoch: 5 : step 70, loss: 1.9853
epoch: 5 : step 80, loss: 1.9778
epoch: 5 : step 90, loss: 1.9683
epoch: 5 : step 100, loss: 1.9611
val_loss: 1.7018
epoch: 6 : step 10, loss: 1.9517
epoch: 6 : step 20, loss: 1.9427
epoch: 6 : step 30, loss: 1.9341
epoch: 6 : step 40, loss: 1.9255
epoch: 6 : step 50, loss: 1.9177
epoch: 6 : step 60, loss: 1.9084
epoch: 6 : step 70, loss: 1.9009
epoch: 6 : step 80, loss: 1.8926
epoch: 6 : step 90, loss: 1.8828
epoch: 6 : step 100, loss: 1.8731
val_loss: 1.3541
epoch: 7 : step 10, loss: 1.8655
epoch: 7 : step 20, loss: 1.8566
epoch: 7 : step 30, loss: 1.8493
epoch: 7 : step 40, loss: 1.8406
epoch: 7 : step 50, loss: 1.8329
epoch: 7 : step 60, loss: 1.8260
epoch: 7 : step 70, loss: 1.8180
epoch: 7 : step 80, loss: 1.8088
epoch: 7 : step 90, loss: 1.8023
epoch: 7 : step 100, loss: 1.7955
val_loss: 1.0189
epoch: 8 : step 10, loss: 1.7876
epoch: 8 : step 20, loss: 1.7805
epoch: 8 : step 30, loss: 1.7740
epoch: 8 : step 40, loss: 1.7653
epoch: 8 : step 50, loss: 1.7580
epoch: 8 : step 60, loss: 1.7516
epoch: 8 : step 70, loss: 1.7442
epoch: 8 : step 80, loss: 1.7368
epoch: 8 : step 90, loss: 1.7295
epoch: 8 : step 100, loss: 1.7228
val_loss: 1.3117
epoch: 9 : step 10, loss: 1.7163
epoch: 9 : step 20, loss: 1.7110
epoch: 9 : step 30, loss: 1.7038
epoch: 9 : step 40, loss: 1.6972
epoch: 9 : step 50, loss: 1.6908
epoch: 9 : step 60, loss: 1.6844
epoch: 9 : step 70, loss: 1.6787
epoch: 9 : step 80, loss: 1.6738
epoch: 9 : step 90, loss: 1.6679
epoch: 9 : step 100, loss: 1.6624
val_loss: 1.0927
epoch: 10 : step 10, loss: 1.6569
epoch: 10 : step 20, loss: 1.6523
epoch: 10 : step 30, loss: 1.6458
epoch: 10 : step 40, loss: 1.6407
epoch: 10 : step 50, loss: 1.6361
epoch: 10 : step 60, loss: 1.6304
epoch: 10 : step 70, loss: 1.6242
epoch: 10 : step 80, loss: 1.6189
epoch: 10 : step 90, loss: 1.6141
epoch: 10 : step 100, loss: 1.6095
val_loss: 0.9826
We also support Tensorboard at http://localhost:8888 you can view your Train loss, and Val loss.